

Удаление дубликатов строк из таблицы в СУБД SQL Server является часто встречающейся задачей для разработчиков и администраторов баз данных. Повторяющиеся строки могут возникать из-за различных причин, таких как ошибки внесения данных или неверные операции объединения.
Однако, если вы столкнулись с подобной проблемой, не волнуйтесь! В этом подробном руководстве мы расскажем вам о нескольких способах удаления дубликатов строк из таблицы SQL Server, включая использование различных ключей и функций.
Перед тем, как приступить к удалению дубликатов, важно выполнить резервное копирование таблицы или создать временную таблицу для тестирования. Также рекомендуется провести анализ повторяющихся строк, чтобы найти наиболее эффективный способ удаления дубликатов в вашей конкретной ситуации.
Ваша цель — обеспечить консистентность и точность данных в таблице, чтобы избежать проблем с запросами и ведением учета. Следуйте нашему подробному руководству, и вы сможете удалить дубликаты строк из таблицы SQL Server без проблем!
- Как удалять дубликаты строк из таблицы SQL Server
- Раздел 1: Подготовка к удалению дубликатов
- Подраздел 1.1: Определение дубликатов
- Подраздел 1.2: Выбор столбцов для проверки дубликатов
- Раздел 2: Удаление дубликатов строк
- Подраздел 2.1: Использование оператора DISTINCT
- Подраздел 2.2: Использование оператора GROUP BY
Как удалять дубликаты строк из таблицы SQL Server
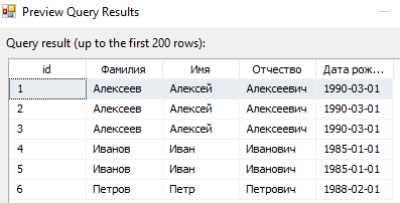
В таблице SQL Server может возникать ситуация, когда данные дублируются, т.е. в таблице присутствуют строки с одинаковыми значениями в некоторых столбцах. Удаление этих дубликатов может быть необходимо для поддержания целостности данных и повышения эффективности работы с таблицей.
Для удаления дубликатов строк из таблицы SQL Server вы можете воспользоваться несколькими методами:
- Использование временной таблицы. Сначала вы создадите временную таблицу с уникальными записями, а затем скопируете данные из временной таблицы обратно в исходную таблицу, заменяя дублирующиеся строки.
- Использование оператора DISTINCT вместе с оператором INSERT. Этот метод позволяет выбрать только уникальные строки из исходной таблицы и вставить их в новую таблицу. Затем вы можете переименовать новую таблицу и удалить исходную таблицу.
- Использование оператора GROUP BY вместе с функцией COUNT и оператором HAVING. С помощью этого метода вы можете сгруппировать строки по выбранным столбцам и выбрать только те группы, у которых количество записей больше единицы. Затем вы можете удалить эти дубликаты.
Выбор определенного метода для удаления дубликатов строк из таблицы SQL Server зависит от ваших конкретных потребностей и ограничений.
Важно иметь в виду, что при удалении дубликатов строк из таблицы SQL Server всегда рекомендуется создавать резервные копии данных или работать с тестовой версией таблицы, чтобы избежать потери важной информации. Также необходимо обеспечить правильность условий для удаления дубликатов, чтобы избежать удаления нужных данных.
Раздел 1: Подготовка к удалению дубликатов
Перед тем, как приступить к удалению дубликатов из таблицы SQL Server, необходимо провести некоторые подготовительные действия. Это позволит избежать потери данных и обеспечить правильное выполнение операции.
1. Сделайте резервную копию таблицы: прежде чем вносить изменения в таблицу, рекомендуется создать резервную копию данных. Это обеспечит возможность восстановления данных в случае непредвиденных ситуаций или ошибок.
2. Определите критерии уникальности: перед удалением дубликатов, нужно определить, какие столбцы или комбинации столбцов должны быть уникальными. Это поможет определить, какие строки являются дубликатами.
3. Подготовьте условия для удаления дубликатов: после определения критериев уникальности, следует подготовить условия, которые позволят удалить дубликаты из таблицы. Это может быть сделано с использованием оператора DELETE или через временную таблицу.
4. Проверьте удаление на тестовых данных: перед применением удаления дубликатов на реальных данных, рекомендуется проверить процедуру на тестовых данных. Это позволит убедиться, что удаление происходит корректно без нежелательных последствий.
Следуя этим шагам, вы будете готовы к удалению дубликатов из таблицы SQL Server, минимизируя риски потери данных и обеспечивая правильное выполнение операции.
Подраздел 1.1: Определение дубликатов
Существует несколько способов определить дубликаты в таблице:
- Определение дубликатов по одному столбцу: вы можете определить дубликаты, сравнивая значения одного столбца и ища строки, которые имеют одинаковые значения в этом столбце.
- Определение дубликатов по нескольким столбцам: вы можете определить дубликаты, сравнивая значения нескольких столбцов и ища строки, которые имеют одинаковые значения во всех этих столбцах.
Для определения дубликатов вы можете использовать операторы SQL, такие как GROUP BY, HAVING и COUNT. Оператор GROUP BY группирует строки по определенным столбцам, оператор HAVING фильтрует группы строк, а оператор COUNT подсчитывает количество строк в каждой группе. Зная эти операторы, вы можете написать запрос SQL, который вернет вам только дубликаты строк.
Подраздел 1.2: Выбор столбцов для проверки дубликатов
Для начала, необходимо определить, какие столбцы в вашей таблице содержат информацию, по которой можно определить дубликаты. Например, если у вас есть таблица «Пользователи» с колонками «Имя», «Фамилия» и «Email», вы можете выбрать все три столбца для проверки на дубликаты.
Однако в некоторых случаях может потребоваться проверка только определенных столбцов. Например, если в таблице «Заказы» у вас есть столбец «Номер заказа», вы можете выбрать этот столбец для проверки дубликатов, поскольку каждый заказ должен иметь уникальный номер.
Важно учитывать, что выбор столбцов для проверки дубликатов зависит от конкретных требований вашего приложения и структуры данных. В некоторых случаях может потребоваться проверка дубликатов по нескольким столбцам одновременно.
Когда вы определите столбцы для проверки дубликатов, вы можете использовать соответствующие инструкции и функции SQL Server для удаления дубликатов из таблицы. Дальнейшие шаги и примеры будут рассмотрены в следующих разделах.
Раздел 2: Удаление дубликатов строк
Существует несколько способов удаления дубликатов строк в SQL Server:
- Использование временной таблицы и операции DELETE
- Использование оконных функций и операции DELETE
- Использование ключевого слова DISTINCT в операции SELECT
Каждый из этих методов имеет свои преимущества и недостатки, и выбор метода будет зависеть от конкретной ситуации и требований к производительности.
Первый метод, использование временной таблицы и операции DELETE, дает возможность сохранить результаты во временной таблице перед удалением дубликатов. Это может быть полезно, если нужно выполнить дополнительные операции с удаленными данными.
Второй метод, использование оконных функций и операции DELETE, позволяет выполнить удаление дубликатов в рамках одного запроса. Оконные функции позволяют нам группировать и нумеровать строки внутри каждой группы. Мы можем использовать эту информацию для удаления дубликатов.
Третий метод, использование ключевого слова DISTINCT в операции SELECT, позволяет получить только уникальные строки из таблицы. Такой подход может быть полезным, если нет необходимости фактически удалять дубликаты строк, а только получить уникальные записи для дальнейшей обработки.
Подраздел 2.1: Использование оператора DISTINCT
Чтобы использовать оператор DISTINCT, нужно включить его в оператор SELECT, после которого указать столбцы, по которым нужно удалить дубликаты. Например, следующий запрос выберет все уникальные значения столбца «имя» из таблицы «пользователи»:
SELECT DISTINCT имя FROM пользователи;
Оператор DISTINCT будет работать только с указанными столбцами, поэтому в результате запроса будут только уникальные значения из выбранных столбцов. В зависимости от ваших потребностей, вы можете указать несколько столбцов после оператора DISTINCT, чтобы удалить дубликаты по этим столбцам.
Оператор DISTINCT применяется только к выбранным столбцам и не влияет на остальные столбцы таблицы. Если вы хотите удалить дубликаты строк целиком, вам следует использовать другие подходы, такие как использование функции ROW_NUMBER() или временной таблицы.
Использование оператора DISTINCT может быть полезно, когда вам нужно быстро получить список уникальных значений из определенного столбца таблицы, без необходимости удаления дубликатов из самой таблицы.
Подраздел 2.2: Использование оператора GROUP BY
Для использования оператора GROUP BY вам необходимо указать столбцы, по которым нужно сгруппировать строки, после чего вы можете применить агрегатные функции к другим столбцам таблицы. Например, в следующем примере мы сгруппируем строки таблицы «Employees» по столбцу «DepartmentID» и вычислим средний возраст сотрудников в каждом отделе:
| DepartmentID | Средний возраст |
|---|---|
| 1 | 35 |
| 2 | 42 |
| 3 | 28 |
В данном примере мы получаем три уникальные группы по значению столбца «DepartmentID» и вычисляем средний возраст сотрудников в каждой группе.
Также оператор GROUP BY позволяет комбинировать несколько столбцов для группировки. Например, мы можем сгруппировать строки таблицы «Orders» по столбцам «CustomerID» и «ProductID» и посчитать количество заказанных товаров каждым клиентом:
| CustomerID | ProductID | Количество заказов |
|---|---|---|
| 1 | 101 | 5 |
| 1 | 102 | 3 |
| 2 | 101 | 2 |
В этом примере мы группируем строки по двум столбцам «CustomerID» и «ProductID» и вычисляем количество заказанных товаров для каждой комбинации этих значений.
Оператор GROUP BY также может использоваться совместно с оператором HAVING, который позволяет фильтровать результаты группировки по определенному условию. Например, мы можем использовать оператор HAVING для отображения только тех групп, в которых количество заказов превышает определенное значение:
| CustomerID | ProductID | Количество заказов |
|---|---|---|
| 1 | 101 | 5 |
В этом примере мы отображаем только ту группу, в которой количество заказов больше 3.
Использование оператора GROUP BY является мощным инструментом для выполнения агрегирующих операций и удаления дубликатов строк из таблицы в SQL Server. Он позволяет группировать данные по одному или нескольким столбцам, применять агрегатные функции и фильтровать результаты с помощью оператора HAVING.
